CMC Telecom cam kết hỗ trợ doanh nghiệp của bạn kịp thời
Hãy gửi phản hồi và câu hỏi của bạn cho chúng tôi để được giải đáp


Làm thế nào để quản lý chi phí AI tạo sinh (GenAI) một cách hiệu quả mà không phải hy sinh hiệu năng và tính sẵn sàng của ứng dụng? Đây là câu hỏi lớn mà nhiều doanh nghiệp đang đối mặt. Google Cloud cung cấp một loạt các tùy chọn hạ tầng linh hoạt, từ mô hình thanh toán theo mức sử dụng (Pay-as-you-Go) đến các giải pháp chuyên biệt, giúp doanh nghiệp tìm ra điểm cân bằng tối ưu giữa chi phí và hiệu năng.
Đối với nhiều workload, các gói PayGo tiêu chuẩn của Google Cloud là một điểm khởi đầu mạnh mẽ và linh hoạt. Để tận dụng tối đa, doanh nghiệp cần hiểu rõ các cơ chế quản lý hiệu năng và tính sẵn sàng.
Về cơ bản, môi trường PayGo tiêu chuẩn hoạt động dựa trên một nguyên tắc về sự công bằng và hiệu quả gọi là Dynamic Shared Quota (DSQ). Thay vì áp đặt các giới hạn cứng nhắc cho mỗi khách hàng, DSQ phân phối dung lượng GenAI có sẵn một cách thông minh cho tất cả người dùng.
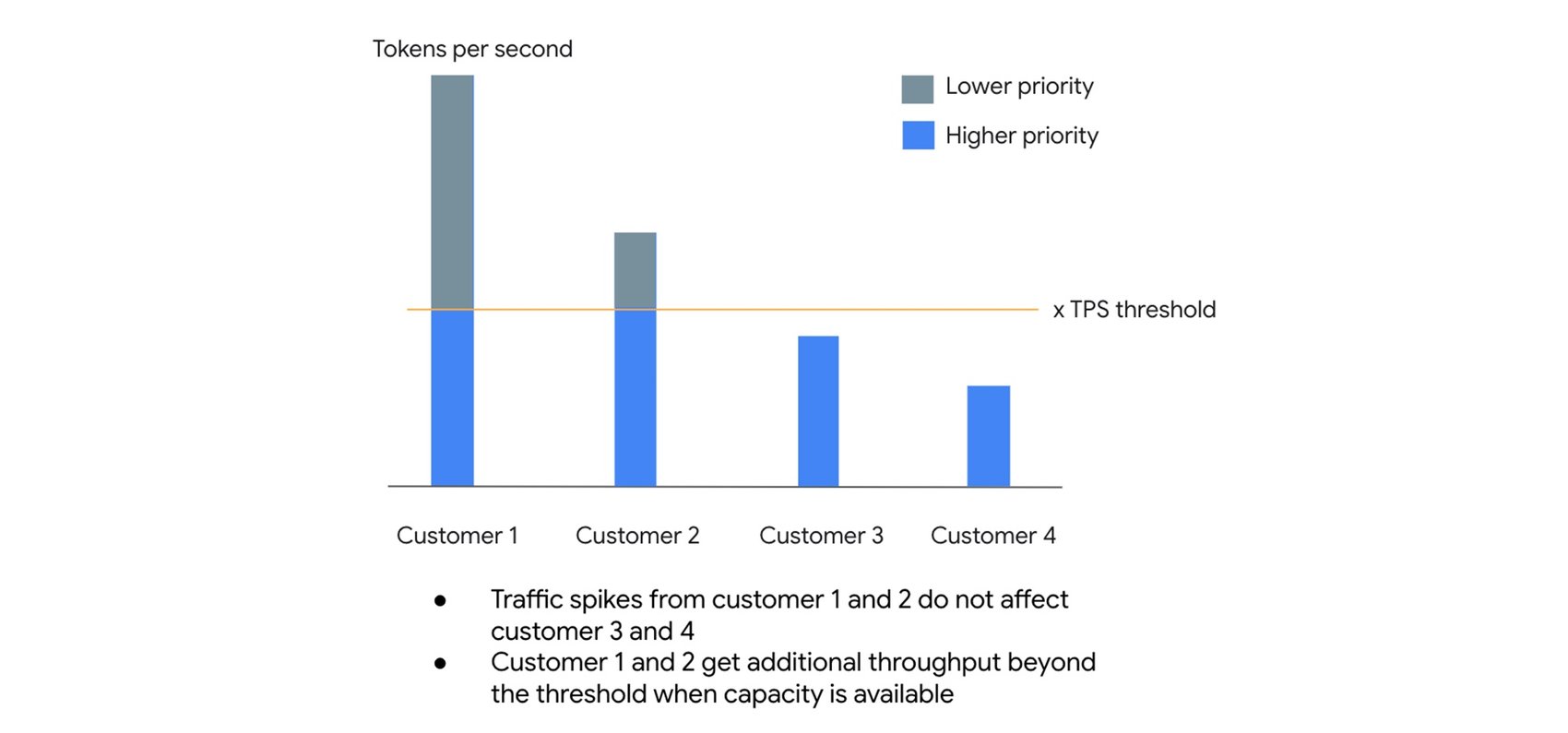
Cách hoạt động:
Để cung cấp hiệu năng dễ dự đoán hơn khi việc sử dụng GenAI của bạn tăng lên, Google Cloud tự động xếp tổ chức của bạn vào các Hạng mục sử dụng (Usage Tiers) dựa trên chi tiêu trong 30 ngày gần nhất cho các dịch vụ Vertex AI đủ điều kiện. Hạng càng cao, giới hạn Tokens Per Minute (TPM) được đảm bảo càng lớn.
Tại thời điểm bài viết gốc được công bố, đây là các hạng mục cho các họ mô hình phổ biến của Google Cloud:
| Họ Mô hình | Hạng | Chi tiêu (30 ngày) | TPM |
|---|---|---|---|
| Pro Models | Tier 1 | $10 – $250 | 500,000 |
| Tier 2 | $250 – $2,000 | 1,000,000 | |
| Tier 3 | > $2,000 | 2,000,000 | |
| Flash / Flash-Lite Models | 4,000,000 / 10,000,000 |
Lưu ý: Để có thông tin mới nhất về mô hình và ngưỡng, doanh nghiệp nên tham khảo tài liệu chính thức.
Điều quan trọng là nên xem giới hạn theo hạng là mức sàn, không phải mức trần.
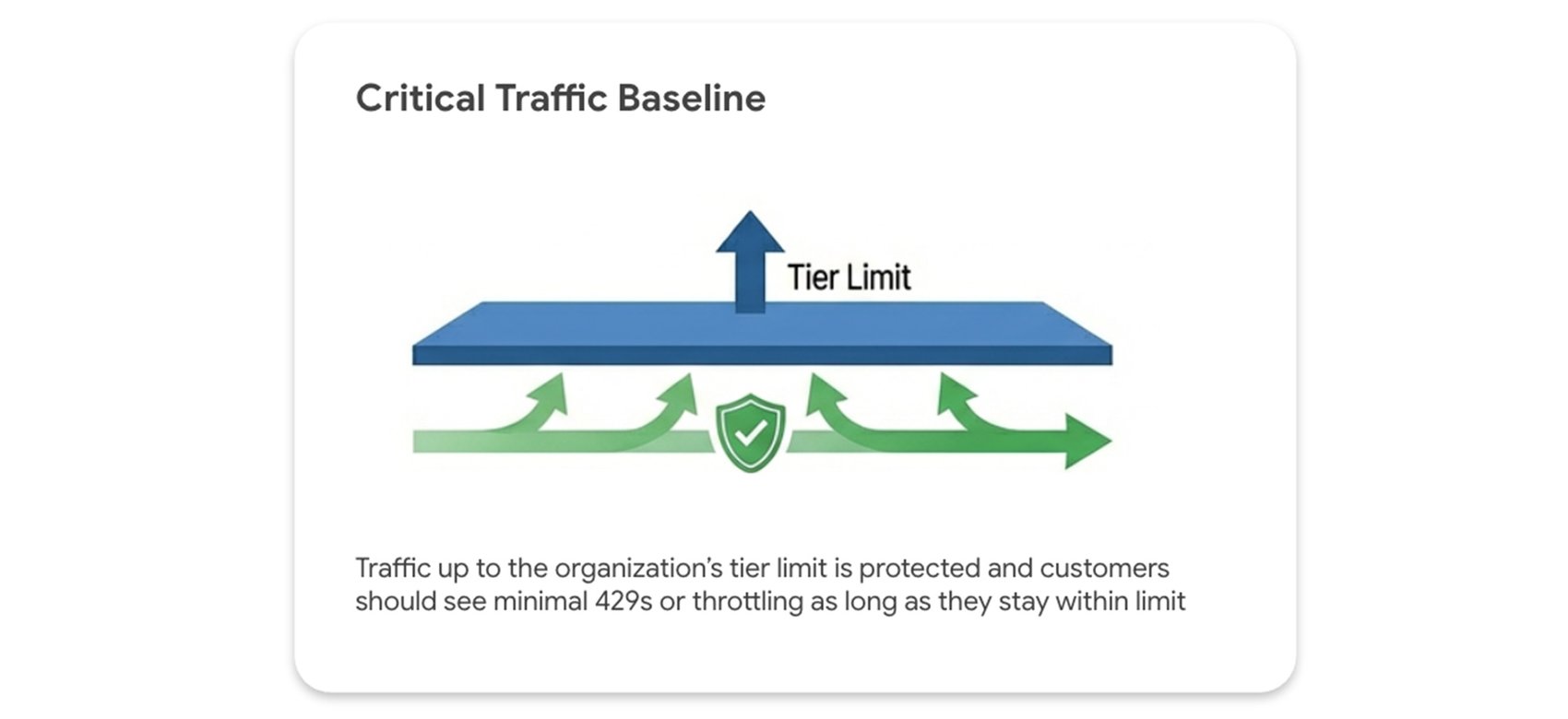
429 (hết tài nguyên) miễn là duy trì trong mức cơ bản này.Nếu workload của bạn dễ có những đột biến không thể đoán trước và không thể chấp nhận rủi ro lỗi 429, nhưng chưa sẵn sàng cam kết một mô hình dung lượng cố định, Priority PayGo là giải pháp. Nó kết hợp sự linh hoạt của PayGo với tính sẵn sàng cao cần thiết cho traffic quan trọng.
Với một khoản phí bổ sung, bạn có thể gắn thẻ các request API cụ thể để được ưu tiên cao hơn.
Lưu ý: Tính năng Priority PayGo hiện chỉ khả dụng cho endpoint toàn cầu. Việc phát hành trên các endpoint khu vực trong tương lai có thể xảy ra nhưng không được đảm bảo.
Để sử dụng Priority PayGo, chỉ cần thêm một header vào lệnh gọi API. Doanh nghiệp cần lưu ý đến giới hạn tăng tốc (ramp limit). Như các hình ảnh dưới đây minh họa, việc tăng các request ưu tiên quá nhanh có thể khiến một số request bị hạ cấp xuống mức ưu tiên tiêu chuẩn nếu dung lượng bị hạn chế.
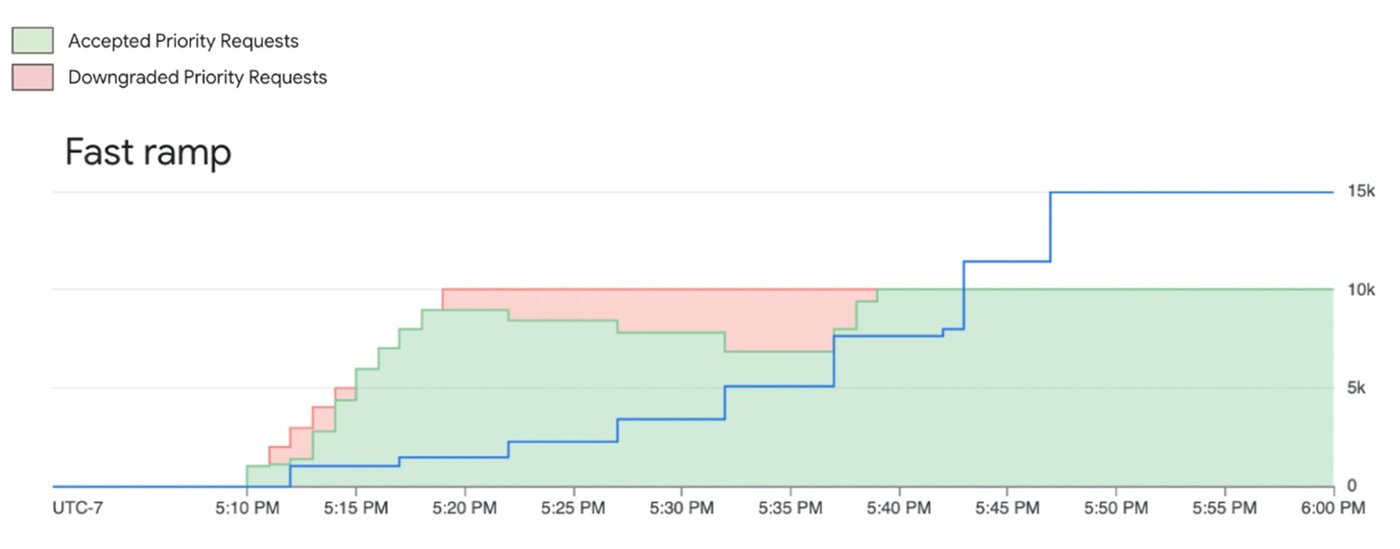
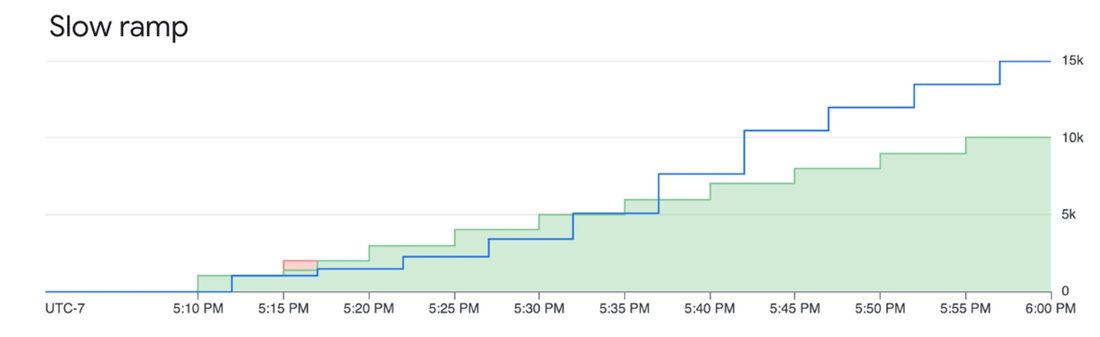
Khi workload GenAI của bạn mang tính sống còn đối với hoạt động kinh doanh và cần một cam kết rõ ràng về tính sẵn sàng, đã đến lúc xem xét Provisioned Throughput (PT). Với PT, bạn đặt trước một lượng dung lượng xử lý mô hình cụ thể với chi phí cố định hàng tháng. Đây là cách duy nhất để nhận được cam kết chất lượng dịch vụ về tính sẵn sàng (availability SLA).
Trong khi mô hình PayGo tiêu chuẩn có uptime SLA (mô hình đang hoạt động), PT cung cấp availability SLA (request của bạn sẽ được xử lý). Đối với PT tiêu chuẩn, khi bạn sử dụng ít hơn lượng đã mua, các lỗi mà lẽ ra là 429 (hết tài nguyên) sẽ được trả về dưới dạng 5XX và được tính vào tỷ lệ lỗi của SLA. Điều này làm cho PT trở thành lựa chọn lý tưởng cho:
Mặc định, mọi mức sử dụng vượt quá đơn hàng PT của bạn sẽ tự động chuyển sang PayGo. Tuy nhiên, bạn có thể kiểm soát hành vi này ở cấp độ request bằng cách sử dụng các HTTP header:
dedicated.shared.Bạn có thể giám sát chặt chẽ việc sử dụng Provisioned Throughput bằng các chỉ số Cloud Monitoring trên tài nguyên aiplatform.googleapis.com/PublisherModel.
Hãy xem xét một workload có mức tải cơ bản hàng ngày có thể dự đoán, các đỉnh dự kiến và các đột biến bất ngờ. Chiến lược tối ưu sẽ là:
Không phải mọi request LLM đều cần thời gian phản hồi dưới một giây. Đây là lúc Gemini Batch API trở nên hữu ích. Khách hàng có thể gộp một lượng lớn request vào một tệp duy nhất và gửi đi một cách bất đồng bộ. Bằng cách đánh đổi việc thực thi ngay lập tức để lấy xử lý bất đồng bộ, bạn sẽ được giảm giá 50% so với chi phí token tiêu chuẩn.
Trong khi đó, Flex PayGo cung cấp một cách truy cập các mô hình Gemini hiệu quả về chi phí, giảm giá 50% so với Standard PayGo. Nó được tối ưu hóa cho các workload không quan trọng có thể chấp nhận thời gian phản hồi lên đến 30 phút. Các trường hợp sử dụng lý tưởng bao gồm:
Để tìm hiểu sâu hơn, doanh nghiệp có thể:
Hãy gửi phản hồi và câu hỏi của bạn cho chúng tôi để được giải đáp