Xây dựng ứng dụng LLM trên Vertex AI: 5 chiến lược giảm lỗi và tối ưu hiệu năng
Jun 2, 2026
-
18 views
Share:
Khi xây dựng các ứng dụng dựa trên mô hình ngôn ngữ lớn (LLM) trên Vertex AI, việc gặp phải lỗi 429 (Resource Exhausted) có thể gây gián đoạn trải nghiệm người dùng và cản trở khả năng mở rộng. Lỗi này xảy ra khi số lượng yêu cầu gửi đến vượt quá khả năng xử lý của dịch vụ tại một thời điểm. Bài viết này sẽ phân tích các mô hình sử dụng của Vertex AI và các phương pháp kiến trúc tốt nhất để quản lý luồng yêu cầu, giúp doanh nghiệp xây dựng các ứng dụng AI ổn định, bền vững và có khả năng mở rộng thực sự.
Lựa chọn mô hình sử dụng phù hợp
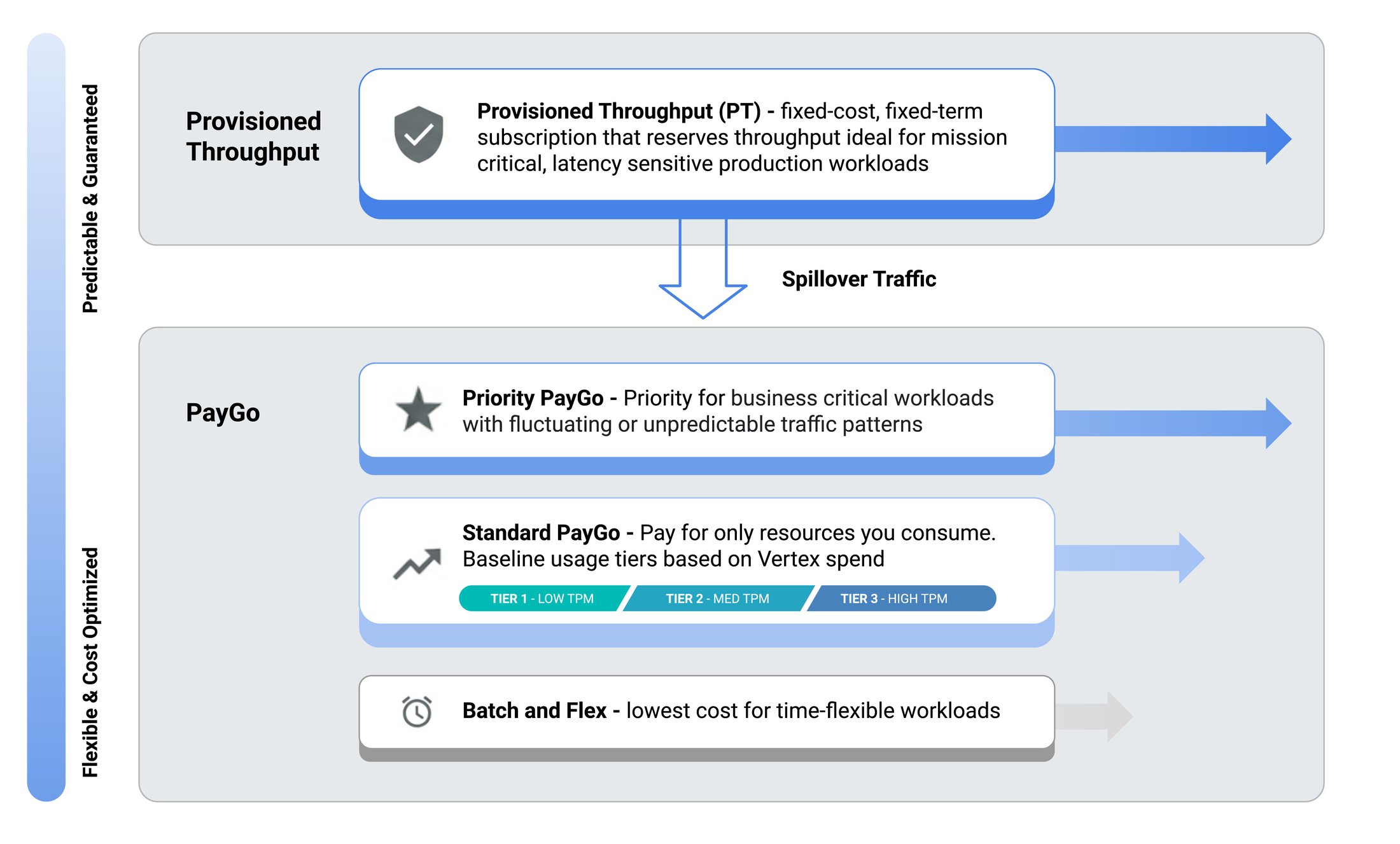
Chiến lược chính để giảm thiểu lỗi 429 là chọn mô hình sử dụng (consumption model) phù hợp nhất với đặc điểm lưu lượng truy cập của ứng dụng. Google Cloud cung cấp nhiều tùy chọn trên Vertex AI để đáp ứng các loại và khối lượng traffic API khác nhau.
Tùy chọn mặc định (Pay-as-you-go): Với Gemini trên Vertex AI, tùy chọn mặc định là Standard Pay-as-you-go (Paygo). Vertex AI sử dụng hệ thống Bậc sử dụng (Usage Tiers), phân bổ tài nguyên từ một nguồn chia sẻ. Mức chi tiêu lịch sử của tổ chức sẽ xác định Bậc sử dụng và thông lượng (TPM) cơ bản, tạo ra một mức hiệu năng sàn có thể dự đoán cho các workload thông thường, đồng thời cho phép ứng dụng bùng nổ vượt mức cơ bản trên cơ sở nỗ lực tốt nhất.
Ưu tiên cho traffic quan trọng: Nếu ứng dụng có traffic quan trọng, hướng tới người dùng, không thể dự đoán và yêu cầu độ tin cậy cao hơn, Priority Paygo là lựa chọn phù hợp. Bằng cách thêm header ưu tiên vào yêu cầu, doanh nghiệp báo hiệu rằng traffic này cần được ưu tiên, giảm khả năng bị điều tiết (throttled).
Đảm bảo thông lượng: Đối với các ứng dụng có lưu lượng traffic thời gian thực cao và ổn định, Provisioned Throughput (PT) là lựa chọn duy nhất cung cấp sự tách biệt khỏi nhóm Paygo dùng chung, mang lại trải nghiệm ổn định ngay cả khi có sự cạnh tranh lớn trên Paygo. Với PT, doanh nghiệp đặt trước và trả phí cho một mức thông lượng được đảm bảo.
Tùy chọn tiết kiệm chi phí: Đối với traffic không nhạy cảm về độ trễ, Flex Paygo xử lý các yêu cầu với mức giá thấp hơn. Các công việc không đồng bộ, quy mô lớn như phân tích ngoại tuyến hoặc làm giàu dữ liệu hàng loạt phù hợp nhất với Batch. Dịch vụ này quản lý toàn bộ quy trình làm việc, bao gồm cả việc mở rộng và retry, trong một khoảng thời gian dài hơn (khoảng 24 giờ).
Phương pháp kết hợp (Hybrid): Các ứng dụng phức tạp thường tận dụng phương pháp kết hợp: PT cho traffic thời gian thực thiết yếu, Priority Paygo cho traffic biến động, Standard Paygo cho các yêu cầu chung, và Batch/Flex cho các luồng yêu cầu không nhạy cảm về độ trễ và ngoại tuyến.
5 phương pháp giảm lỗi 429 trên Vertex AI
Ngoài việc chọn mô hình sử dụng phù hợp, việc áp dụng các phương pháp kiến trúc dưới đây sẽ giúp tăng cường khả năng phục hồi cho ứng dụng.
1. Triển khai cơ chế retry thông minh
Khi gặp lỗi tạm thời như 429 hoặc 503 (Service Unavailable), việc retry ngay lập tức không được khuyến khích. Thay vào đó, hãy triển khai chiến lược Exponential Backoff with Jitter (retry với thời gian chờ tăng theo cấp số nhân và có yếu tố ngẫu nhiên). Điều này cho phép dịch vụ có thời gian phục hồi.
SDK & Thư viện: Google Gen AI SDK đã tích hợp sẵn hành vi retry. Lập trình viên cũng có thể sử dụng các thư viện chuyên dụng như Tenacity (cho Python).
Agentic Workflows: Agent Development Kit (ADK) cung cấp plugin Reflect and Retry để tự động xử lý lỗi 429.
Infrastructure & Gateway: Sử dụng cơ chế circuit breaking với Apigee để quản lý phân phối traffic và xử lý lỗi một cách linh hoạt.
2. Tận dụng định tuyến mô hình toàn cầu (Global Model Routing)
Cơ sở hạ tầng của Vertex AI được phân bổ trên nhiều region. Thay vì bị giới hạn trong một region duy nhất, việc sử dụng endpoint toàn cầu (global endpoint) cho phép định tuyến traffic của bạn đến các region có sẵn tài nguyên, từ đó giảm tỷ lệ lỗi tiềm ẩn và tăng cường tính sẵn sàng.
3. Giảm payload bằng Context Caching
Để giảm tải cho Vertex AI, hãy tránh thực hiện các lệnh gọi cho các truy vấn lặp đi lặp lại. Với Context Caching, Gemini tái sử dụng các token đã được tính toán và lưu vào bộ đệm, giúp bạn giảm lưu lượng API, thông lượng, chi phí và cả độ trễ cho các nội dung lặp lại trong prompt.
4. Tối ưu hóa prompt
Giảm số lượng token trong mỗi yêu cầu sẽ trực tiếp giảm mức tiêu thụ TPM và chi phí.
Tóm tắt ngữ cảnh: Trước khi gửi một lịch sử hội thoại dài cho Gemini Pro, hãy dùng một mô hình gọn nhẹ như Gemini 2.5 Flash-Lite để tóm tắt.
Tối ưu bộ nhớ Agent: Với các workload agentic, hãy tận dụng Vertex AI Agent Engine Memory Bank. Các tính năng như Memory Extraction và Consolidation cho phép chắt lọc các thông tin quan trọng từ cuộc hội thoại.
Vệ sinh prompt: Xem xét và giảm bớt các mô tả schema JSON dài dòng, loại bỏ khoảng trắng thừa hoặc định dạng không cần thiết.
5. Điều tiết lưu lượng truy cập (Traffic Shaping)
Sự gia tăng đột biến của các yêu cầu là nguyên nhân chính gây ra lỗi 429. Ngay cả khi tốc độ traffic trung bình thấp, các đỉnh nhọn có thể làm cạn kiệt tài nguyên. Mục tiêu là làm phẳng lưu lượng truy cập, dàn trải các yêu cầu theo thời gian để tránh quá tải.