CMC Telecom cam kết hỗ trợ doanh nghiệp của bạn kịp thời
Hãy gửi phản hồi và câu hỏi của bạn cho chúng tôi để được giải đáp


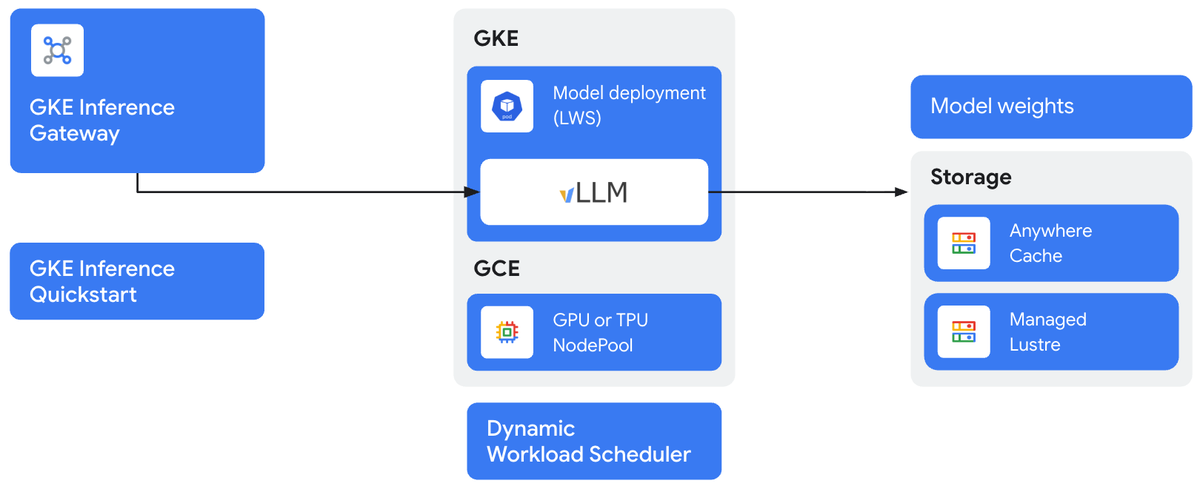
Google Cloud đã chính thức phát hành (GA) GKE Inference Gateway và GKE Inference Quickstart, hai công cụ mạnh mẽ giúp doanh nghiệp tối ưu đáng kể chi phí và hiệu năng khi triển khai các ứng dụng AI tạo sinh. Các tính năng mới này giúp giảm độ trễ, tăng thông lượng và đơn giản hóa việc lựa chọn hạ tầng, cho phép các công ty cung cấp các dịch vụ thông minh hơn một cách hiệu quả.
Các giải pháp inference của Google Cloud được xây dựng trên nền tảng AI Hypercomputer, một hệ thống được thiết kế dựa trên kinh nghiệm vận hành các mô hình quy mô lớn như Gemini và Veo 3. Nền tảng này cung cấp khả năng quản lý tài nguyên, tối ưu hóa workload, định tuyến thông minh và lưu trữ tiên tiến để đạt hiệu suất cao nhất trên các bộ tăng tốc GPU và TPU hàng đầu.
Trải nghiệm người dùng đối với một ứng dụng AI tạo sinh phụ thuộc rất nhiều vào hai chỉ số: time-to-first-token (TTFT – thời gian để nhận được token đầu tiên) và time-per-output-token (TPOT – thời gian cho mỗi token đầu ra). Google Cloud đã cải thiện cả hai chỉ số này thông qua các tính năng mới trên AI Hypercomputer.
Một trong những cải tiến quan trọng là prefix-aware load balancing, hiện đã khả dụng chính thức (GA) trong GKE Inference Gateway. Tính năng này giúp giảm độ trễ TTFT lên đến 96% ở mức thông lượng cao nhất cho các workload có nhiều tiền tố lặp lại (ví dụ: các cuộc hội thoại chatbot). Bằng cách định tuyến thông minh các yêu cầu có cùng tiền tố đến cùng một bộ tăng tốc, hệ thống có thể tái sử dụng KV cache (bộ nhớ đệm khóa-giá trị) đã được tính toán trước, tránh tình trạng quá tải và tăng vọt độ trễ.
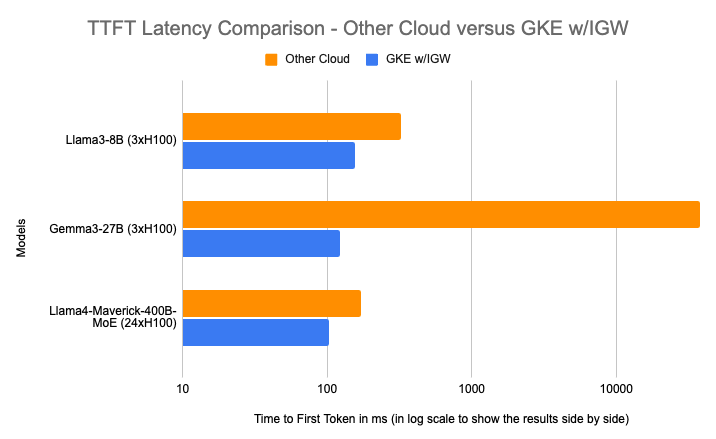
Ví dụ, với một chatbot dịch vụ tài chính, khi người dùng hỏi các câu hỏi nối tiếp về một giao dịch, hệ thống không cần xử lý lại toàn bộ truy vấn ban đầu. Thay vào đó, nó tái sử dụng dữ liệu từ câu hỏi đầu tiên, giúp trả lời gần như tức thì. Việc giảm tính toán này cũng đồng nghĩa với việc cần ít bộ tăng tốc hơn cho cùng một workload, mang lại hiệu quả tiết kiệm chi phí đáng kể.
Để tối ưu hơn nữa, doanh nghiệp giờ đây có thể chạy disaggregated serving (phục vụ phân tách) bằng AI Hypercomputer, giúp cải thiện thông lượng lên đến 60%. Kiến trúc này tách biệt prefill phase (giai đoạn tiền xử lý, cần nhiều năng lực tính toán) và decode phase (giai đoạn giải mã, cần nhiều bộ nhớ) ra các node riêng biệt. Điều này cho phép tối ưu và co giãn độc lập từng giai đoạn, tăng hiệu quả sử dụng tài nguyên và giảm độ trễ cho các ứng dụng như hoàn thiện mã (code completion).
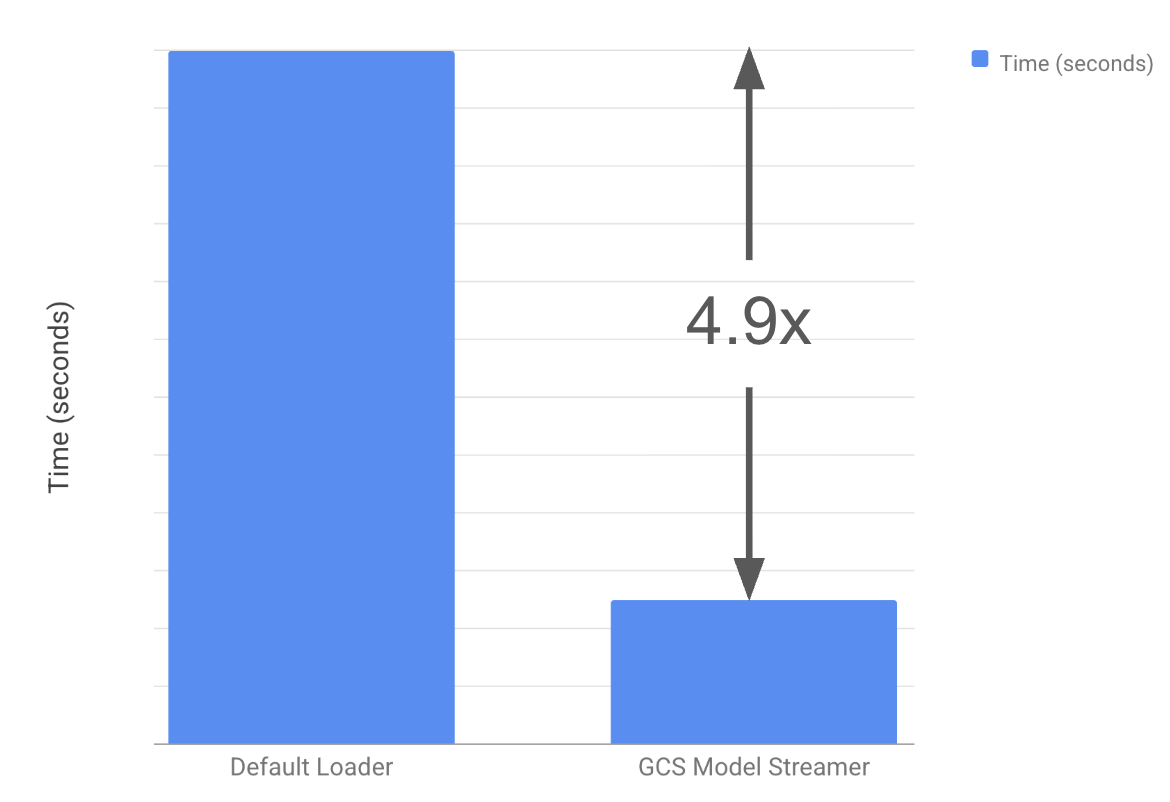
Khi các mô hình AI ngày càng lớn, lên tới hàng trăm gigabyte, thời gian tải chúng có thể mất hơn mười phút, gây chậm trễ trong việc khởi động và mở rộng quy mô. Để giải quyết thách thức này, Google Cloud hiện hỗ trợ Run:ai model streamer tích hợp với Google Cloud Storage và Anywhere Cache cho vLLM.
Giải pháp này cho phép truyền dữ liệu trực tiếp đến bộ nhớ của bộ tăng tốc với tốc độ 5.4 GiB/s, giúp giảm thời gian tải mô hình hơn 4.9 lần. Nhờ đó, doanh nghiệp có thể khởi động và mở rộng các dịch vụ AI nhanh hơn, cải thiện trải nghiệm người dùng cuối.
Việc tìm ra ngăn xếp công nghệ lý tưởng để phục vụ các mô hình AI là một thách thức lớn. Các doanh nghiệp thường phải mất hàng tuần, thậm chí hàng tháng để thử nghiệm và đánh giá vô số sự kết hợp giữa mô hình, bộ tăng tốc và kiến trúc triển khai.
GKE Inference Quickstart, hiện đã khả dụng chính thức (GA), giúp giải quyết vấn đề này bằng cách cung cấp các đề xuất dựa trên dữ liệu để tìm ra cấu hình có hiệu suất-giá tốt nhất. Công cụ này giúp tiết kiệm thời gian, cải thiện hiệu năng và giảm chi phí khi triển khai workload AI.
Các đề xuất của GKE Inference Quickstart dựa trên một kho dữ liệu hiệu năng được cập nhật liên tục. Google Cloud thực hiện benchmark các bộ tăng tốc GPU và TPU của mình với các LLM hàng đầu như Llama, Mixtral và Gemma hơn 100 lần mỗi tuần. Dữ liệu này sau đó được kết hợp với các tối ưu hóa về lưu trữ, mạng và phần mềm đã được kiểm chứng trên các dịch vụ quy mô toàn cầu của Google như Gemini, Search và YouTube.
Với GKE Inference Quickstart, quá trình đánh giá và kiểm định của doanh nghiệp có thể rút ngắn từ hàng tháng xuống chỉ còn vài ngày. Các kỹ sư có thể sử dụng Google Colab để so sánh chi phí, độ trễ và chất lượng của các mô hình khác nhau, từ đó đưa ra quyết định sáng suốt và nhanh chóng triển khai môi trường inference tối ưu trên GKE.
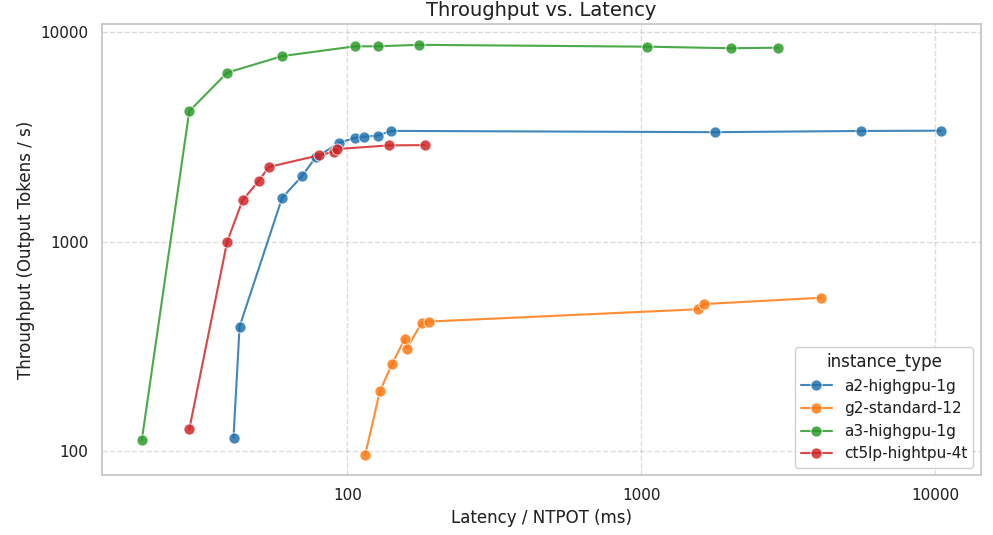
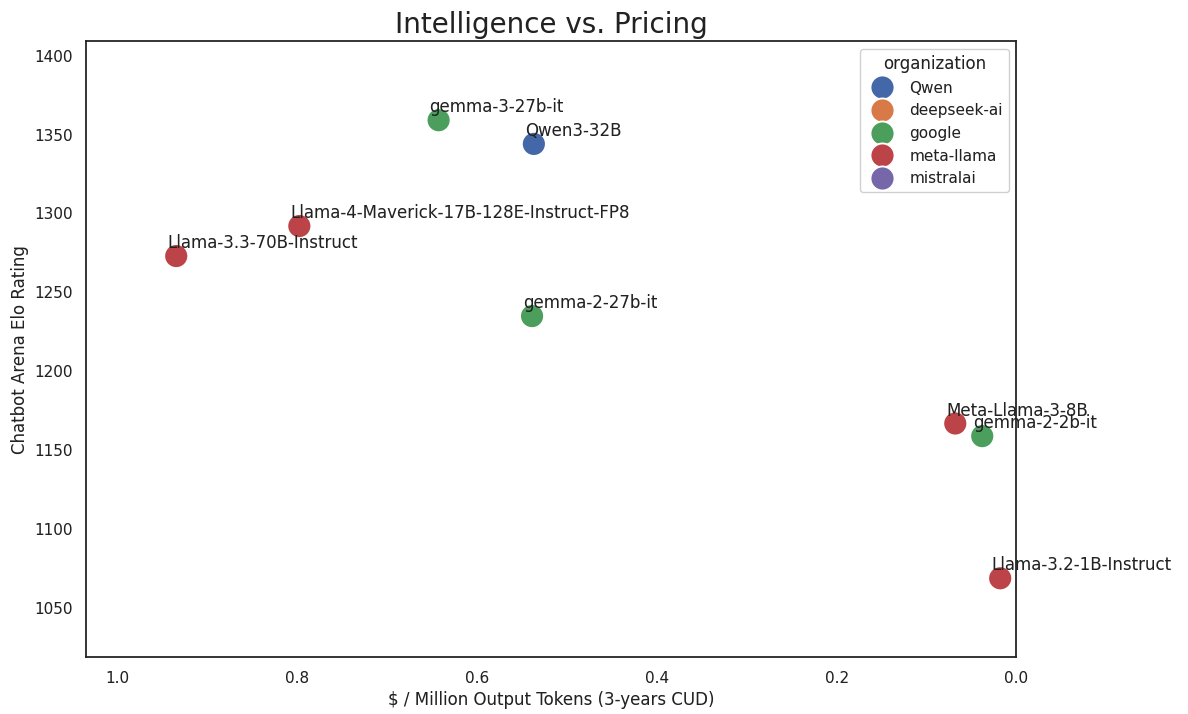
Từ Google Cloud console, người dùng có thể dễ dàng chọn mô hình, thiết lập yêu cầu về độ trễ, và công cụ sẽ tự động đề xuất các bộ tăng tốc tương thích cùng với ước tính chi phí trên mỗi triệu token đầu ra.
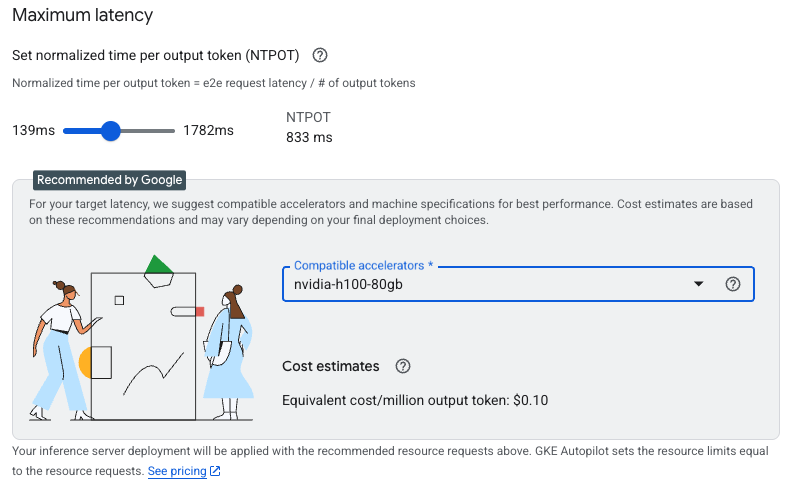
Google Cloud cam kết giúp các doanh nghiệp triển khai và cải thiện các workload AI inference ở quy mô lớn. Bằng cách tận dụng một ngăn xếp được đồng thiết kế gồm các cải tiến phần cứng và phần mềm hàng đầu—bao gồm AI Hypercomputer, GKE Inference Gateway và các tối ưu hóa chuyên dụng—doanh nghiệp có thể cung cấp các dịch vụ thông minh hơn với trải nghiệm người dùng nhanh hơn, phản hồi tốt hơn và tổng chi phí sở hữu (TCO) thấp hơn.
Hãy gửi phản hồi và câu hỏi của bạn cho chúng tôi để được giải đáp